
Big Data comprises various structured, semi-structured, and unstructured data from discrete sources, which can be in any format like text files, images, audio, etc. Most organizations collect data in an unstructured format, and hence the storage, retrieval, and analysis of these large volumes of data are not possible with traditional databases (Oracle, SQL, MySQL, etc.) due to the unstructured format of the data. Big Data is characterized primarily by five V’s – Volume, Velocity, Variety, Veracity, and Value of data; where volume describes the amount of the data collected from various sources, velocity describes the speed(handling and processing rates), variety describes the formats of data(structured, semi-structured or unstructured), veracity explains how much you can trust the data legitimacy, and value is an indicator of how useful the data is for any sort of analysis
Big Data Layers
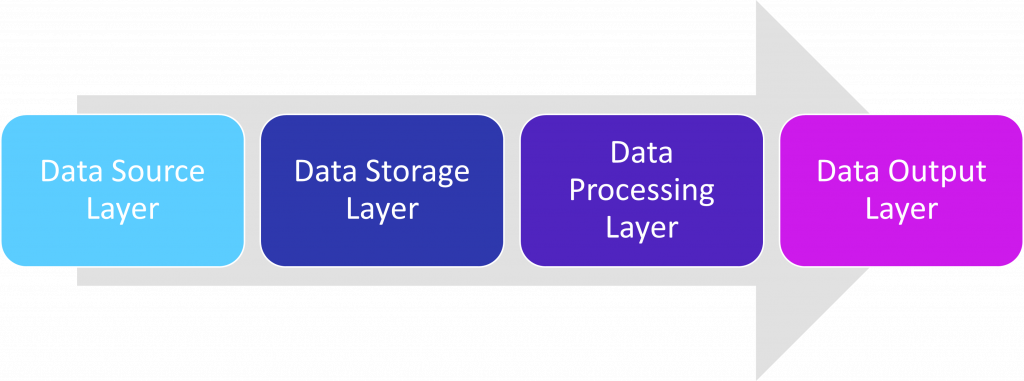
Data Source Layer-This is the first stage of the data layer where data accumulates from various sources.
Data Storage Layer-This is where data gets stored once it is collected from various sources.
Data Processing Layer-This phase analyzes the data collected from the data storage layer to derive insights from it.
Data Output Layer-In this layer, insights gained from the analysis phase will be transferred to the end-user.
Big Data Testing Strategy
When it comes to Big Data testing, there are some critical areas where testing plays a vital role in finding key business insights. Lack of these may result in errors in the system and wastage of revenue, resources, and time. Experian Data Qualityreports, “75% of businesses are wasting 14% of revenue due to poor data quality.” And similarly, a report by Gartnersays, “The average organization loses $14.2 million annually through poor data quality.”
Big data testing can be classified into two phases, one is functional, and the other is non-functional testing. These are not about the tools and technologies but rather about testing the quality and processing of the data.
Functional Testing
Functional testing consists of testing the front-end application based on user requirements. This test will evaluate the complete workflow from data ingestion to data output.
There are three stages for functional testing namely,
- Pre-Hadoop Process Testing: In this stage, the data extracted from various sources such as weblogs, social media, RDBMS, etc. are uploaded into HDFS (Hadoop Distributed File System). The initial stage of testing is carried out in the following order:
- Validation of the data from the source if it’s corrupted
- Data files validation if they are loaded into the accurate HDFS location
- Determine the complete set of data needs to be checked
- File partition checking and copying to separate data units
- Synchronizing the source data with data uploaded into HDFS
- MapReduce Process Validation: MapReduce process is a concept of compressing a large volume of data into standard compact data packets. The process validates the business logic at all nodes, creates the key-value pair, compresses the data, and checks if the output generated data matches with the input files to meet the business requirements.
- Extract-Transform-Load (ETL) Process Validation and Report Testing: ETL (Extraction, Transformation, Load) is the last stage of testing where data is first unloaded from data generated by the previous stage, then transformed into a standard file format and finally loaded into Enterprise Data Warehouse (EDW) where reports are created for further processing. Report testing checks the validation of output data with business requirements.
Non-functional Testing
Non-functional testing can be done in two stages; one is performance testing for job completion time, memory utilization, and validity of data throughput with the business requirements. It tests the response time, maximum data processing capacity, and velocity of the data, assessment of performance limitations, storage of data validation, connection timeout, and query timeout.
Second is Failover testing; it is done to verify if the data processing is seamless in case of failure of data at nodes and validates the recovery process of the data when switched to other data nodes. It is measured in two types of metrics:
• Recovery Time Objective
• Recovery Point Objective
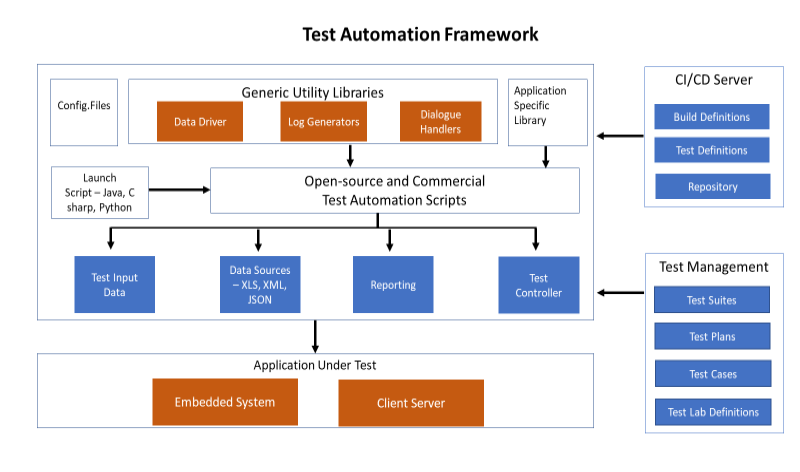
Big Data Automation Testing Approach
In the light of complex and challenging data sets, an automation framework helps to test, deploy, and gain powerful business insights. It is performed in two stages as below:
Database Testing– The first stage of Big Data automation testing is about the testing of the database criteria according to the business requirement. The type and size of incoming data vary across the organization, and we need to understand which database will support the cause to meet the desired result. Data from various sources should be validated to make sure that the correct data format is pulled into the system.
Performance Testing– It further demonstrates the data integrity, data ingestion, data processing, and data storage phase.
Data Ingestion and Throughput-During the process of Data Ingestion, the data is loaded from the source to the database using data extraction tools and cross-checked for any errors and missing values. The data format from CSV, XML, etc. is converted to a standard JSON file, and the file is checked for duplicate or missing values. Further, the rate of data consumption from the source and the speed at which it keeps data in storage is considered for better processing of the data.
Data Processing-In this stage, key data value-pairs are generated, and logic is applied to all the nodes and checked if the algorithm works fine or not.
Sub-system Performance-This stage consists of multiple sub-components, and it is essential to check each component separately as to how data is being consumed and indexed, data log, algorithm validity, search query, etc. It also talks about the value and scalability of the system.
Benefits of Using Big Data Automation Testing
- Significant time reduction in test data creation
- Faster time to market
- Scalable framework
- Reduced QA functional test cycle
- Quality costs and increased revenue
Big Data Testing Best Practices
- Plan load coverage at the outset instead of the sampling approach. Consider deploying an automation tool for access to data across different layers.
- Develop patterns and learning algorithms by using predictive analytics from the insights and data to determine the customer’s needs and interests.
- Behavior analysis of the data model using analytics and alerts with predefined results.
- Ensure correct algorithms and computational methodology with proper KPIs are in place.
- Collaboration with stakeholders for effective execution of incorporating any changes in reporting or dashboard standards.
- Deploy adequate configuration management tools and processes.
Conclusion:
It is evident that big data testing is a crucial phase, and it has its own challenges in terms of technical expertise for automation testing, and real-time data testing as the quantity of data is extensive; hence the time factor always plays a vital role. Big Data Automation Testing is the key to success for the organization as it resolves impractical manual testing errors and is time-consuming due to the large size volume and variety of data. Big Data is not only about the amount of incoming data but the business gains from these data. Organizations need to think about improving customers’ experience with businesses, brands, services, and products. Start small, scale big.