
In the age of self-service business intelligence, nearly every company is at some stage of transitioning to becoming a data-first company. To make the transition a successful one, companies need to undertake this journey with a level of sophistication that involves strategic thinking and purposeful execution.
A Gartner report predicted that “By 2024, 75% of organizations will have established a centralized data and analytics (D&A) center of excellence to support federated D&A initiatives and prevent enterprise failure.”
Indeed, this is not surprising given that the current data architectures are not well equipped to handle data’s ubiquitous and increasingly complex, interconnected nature.
While attempting to address this issue, many companies’ questions remain: How can we best build our data architecture to maximize data efficiency for the growing complexity of data and its use cases?
In this article, we discuss the common data management challenges faced by organizations, DataLakes as an improvement over traditional management tools, and the shift towards Data-Mesh architecture.
Key Challenges in Data Management
Despite the rapid advancement in hardware technologies and architectural models over the past several years, data management still suffers in different measures from:
- Ubiquity: With new domains being integrated into the enterprise and third-party data being piped in for analytics, the quantity, and types of data continue to expand (structured/unstructured, batch/streaming…). This requires an intelligent system that can efficiently transform the data from any one of many original formats to a normalized one either at the time of ingestion or when served up for consumption.
- Ownership: Sourcing experts best understand the data semantics but are often removed from the downstream processes of ingesting, cleaning, and deploying it for analytics. This creates major bottlenecks as the data engineers mediate between consumers and producers of the data on issues relating to quality and semantics.
- Redundancy: Data required for any analytics purpose must be brought together into a unified store. Different consumer systems creating their own analytics repositories result in duplication of data and mismatch due to a lack of synchronization across systems.
- Infrastructure: The tools required to ingest, transform, and store data for analytics uses are complex and require experienced data engineers, creating a bottleneck in setting up and maintaining repositories with multiple sources.
- Scope: Existing systems are designed with current needs and some expectation of new sources. As business users use the system and begin to apply it to different purposes, user needs evolve and expand. Furthermore, with analytics becoming the primary driving force, organizations often want to bring in more data from disparate sources to aid in the existing analytics and build additional capabilities.
- Discoverability & Addressability: The lack of a centrally maintained discovery catalog in traditional systems is a major hindrance to locating and contextualizing the different types of data needed for complex analyses.
The Lake Approach
The Data-Lake architecture evolved as a potential solution to the issues companies faced in their efforts toward building enterprise analytics-ready Data Warehouses.
What is the Data-Lake architecture?
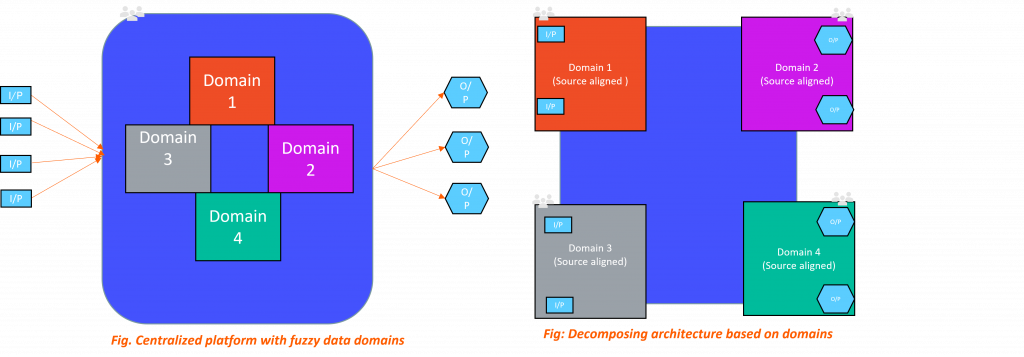
The Data Lake architecture promotes a monolithic, centralized, and domain-agnostic data management system. The premise of this model is to house data relating to all logical domains and use cases for a company in a single centralized store to which all concerned parties have access.
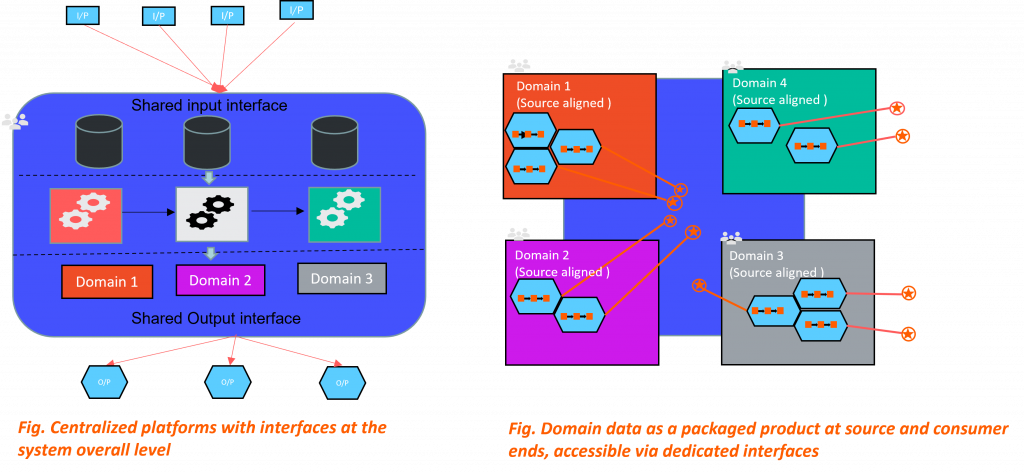
Since data is made available in its source form in a Data Lake repository, it gets registered in the Lake as soon as it becomes available from the source systems. Downstream consumers can then deploy processes to identify, explore, clean, merge or otherwise repurpose the relevant data to generate meaningful insights. Since such processes are context-specific, a separate pipeline is required to handle each consumer need.
This architecture is well equipped to handle real-time streaming data, and unification of batch and stream data, and can easily be deployed and maintained on the cloud, making it an easy choice instead of expensive Data Warehouse solutions.
Where the Data Lake falls short
- Complexity: With the ubiquitous availability of data, the ability to bring it all into a centralized storage system is easy. But harmonizing data from different sources as part of the enrichment process to pull insights becomes a daunting task, and one that gets more complex as the volume and types of data expand.
- Architectural Decomposition: Scaling the data platform is handled at the organization level by specialist teams, each responsible for a part of the enrichment (ETL or ELT) lifecycle. This creates a critical dependency bottleneck and lack of flexibility.
- Operational Challenges: Ownership of the centralized data system is in the hands of a team of people having specialized skillset for handling data, but who are completely siloed from the operational units the data is sourced from. This isolation from business and domain knowledge puts engineers in a position to work with data without context, thus resulting in disconnected source teams, frustrated consumers, and an over-stretched data team.
- Management: Even for skilled engineers, Data Lakes are hard to manage. Ensuring that the host infrastructure has the capacity to scale, dealing with redundant data, securing all the data, etc., are all complex tasks when the data is being stored and managed centrally.
- Accountability & Trust: The distributed ownership of data makes it difficult for consumers to have faith in the quality and integrity of the data. Moreover, identifying the right point of contact for issue resolution is an added challenge.
All of the above-mentioned inherent limitations in the Data Lake’s architecture and organizational structure result in systems that do not scale well and do not always deliver on the promise of creating a data-driven organization.
The Mesh Approach
The Data Mesh approach, introduced by Zhamak Dehghani, evolved out of more holistic thinking about the needs and challenges in the data management process and where prior approaches have failed.
A Data Mesh architecture is technology-agnostic and underpins four main principles that aim to solve major challenges that have plagued data and analytics applications.
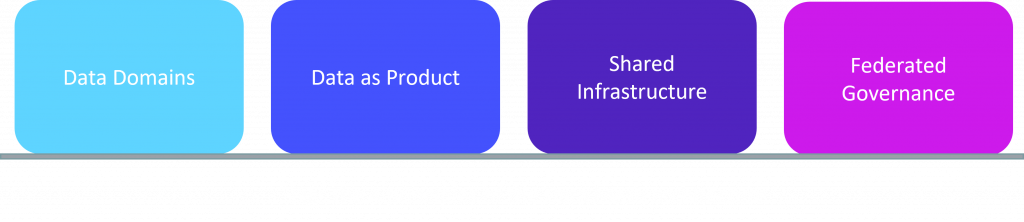
These principles together promote the idea of distributed data products oriented around domains and owned by independent cross-functional teams using self-serve shared infrastructure as a platform to operate on the data, all under centralized governance and standardization for interoperability.
Data Domains
This principle proposes that data is completely owned and controlled by the teams closest to it, thus removing several steps and handoffs between data producers and consumers, whereas in previous architectures ownership was split between multiple teams based on which part of the enrichment process they worked on. This helps overcome Ownership and Accountability issues.
Data as Product
This principle can be summarized as applying product thinking to data. Data becomes a first-class citizen in a Data Mesh, with a dedicated development and operations teams behind it to handle things end-to-end and cater to the data as a packaged product via dedicated interfaces, whereas Data Lakes utilized a shared team for all data-related operations. This helps overcome the Discoverability, Addressability, and Trust issues that plagued previous architectures.
Shared Infrastructure
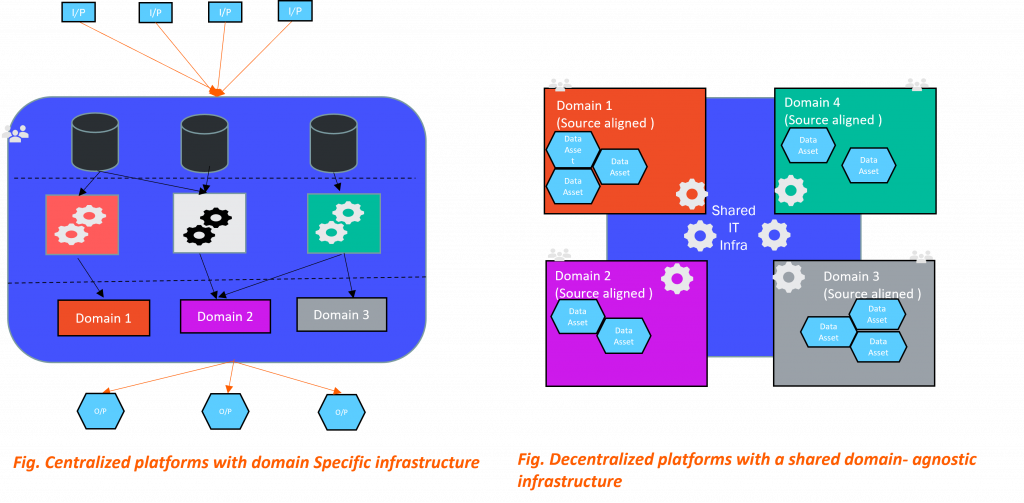
This principle emphasizes providing tools and user-friendly interfaces so that anyone can quickly get access to data or develop analytical data products with speed, and seamlessly. This is critical to minimizing the time from ideation to a working data-driven application. Being in stark contrast to previous architectures where every domain employed its own IT infrastructure and standards, this helps to better optimize the Access and Time-to-Value challenges faced by existing systems.
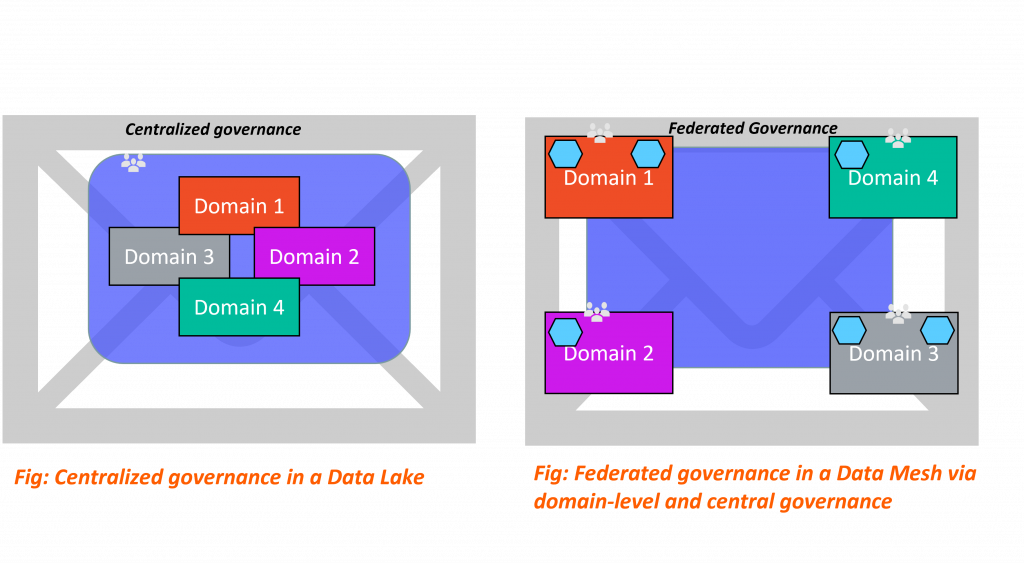
Federated Governance
This principle advocates that data is governed by where it is stored. Acknowledging the dynamic nature of data, we allow each business domain to be responsible for its data governance and security, and the organization can set up general guiding principles to help keep each domain in check. This propagates the idea of better interoperability, something that current systems struggle with.
Implementing a Data-Mesh Architecture
As the world of data and operations is moving to a decentralized paradigm, deploying scalable infrastructures has become easier for organizations by leveraging cloud service providers.
All cloud service providers function on the premise of providing easily accessible infrastructure services to the end user while doing the heavy lifting of procurement, support, and orchestration.
Since the Data Mesh is more of an organizational principle, a holistic out-of-box tool to create one isn’t out there. Most cloud providers have services that only satisfy some of the requirements for building out a Data Mesh. This pushes us to get creative and implement the Data Mesh using a combination of native cloud tools along with other third-party tools in an organized and synchronous manner.
When thinking in terms of a Data Mesh, there are situations where a Data Lake or Data Warehouse still makes sense. Not as the overarching central entity, but as a node in the Mesh, for purposes such as combining data from two domains for intermediate or aggregate analysis. Similarly, if one has an existing Data Lake, it need not be completely discarded while migrating to a Data Mesh architecture. Rather, the Lake can continue to be used while reducing its complexity down to a single domain’s use case.
‘To Mesh or Not to Mesh’
Choosing a data strategy stems from the need to analyze data without having to move or transform it via complex extract, transform, and load (ETL or ELT) pipelines.
For many organizations, the decision to make is whether centralizing data management in a Data Lake is the right approach or is a distributed Data Mesh architecture the right fit for their organization.
Neither of the two options is wrong, but the choice of which one to adopt should account for multiple aspects of an organization’s needs such as:
- How many data sources exist?
- How many analysts, engineers, and product managers does the data team have?
- How many functional teams rely on the data for decision-making?
- How frequently does the data engineering team find itself in a bottleneck?
- How important is data governance for the organization?
A Data Mesh would be helpful for organizations that store data across multiple databases, have a single team handling many data sources, and have a constant need to experiment with data at a rapid rate.
Whereas organizations working with the mindset to upskill employees across the enterprise to become citizen data scientists and looking for a solution that enables data-querying where it lives, in its original form, might benefit more from a Data Lake.