
In today’s data-driven landscape, organizations are constantly challenged with massive volumes of data getting generated at an unprecedented pace. Businesses require a strong infrastructure in order to truly harness the potential of this data. In recent times, Data Mesh and Data Fabric have emerged as reliable solutions to effectively manage large volumes of data. But before we dive deep into these concepts and talk about which approach is better for an organization’s data strategy, let’s first understand how they will impact data management.
According to Oracle, this new kind of data architecture will empower faster innovation cycles and lower costs of operations. Early adopters and pioneers of this approach indicate significant large-scale benefits that are possible today, including:
- Total Clarity into Data’s Value Chain – Can be made possible through applied ‘data product thinking’ best practices.
- More than 99.999% Operational Data Availability – Can be made possible using microservices-based data pipelines for replication.
- 10X Faster Innovation Cycles – Can be made possible by shifting away from extract, transfer and load (ETL) to continuous transformation and loading (CTL).
- Up to 70% Reduction in Data Engineering – Can be made possible using no-code and self-serve data pipeline tooling.
Data Mesh: Decentralization of Data Ownership & Management
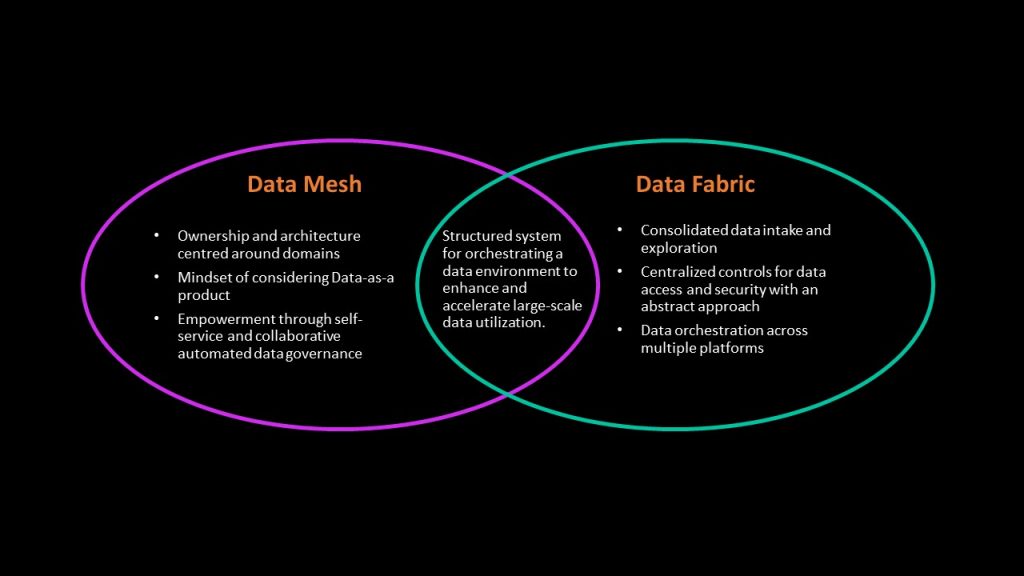
First introduced by Zhamak Dehghani in 2020, Data Mesh is a groundbreaking approach to data architecture that aims to solve the challenges associated with centralized data management. It advocates for a domain-oriented, decentralized approach where data is treated as a product, and individual domains or business units are responsible for their own data infrastructure. The goal is to foster better collaboration between data engineers, data scientists, and domain experts.
In Data Mesh, data is organized into self-contained, autonomous data domains with each domain having its own data products, pipelines, and services. This not only helps an organization improve data ownership and accountability but also enables scalability and agility. The integration of data domains is facilitated through standardized interfaces and APIs, ensuring interoperability across an enterprise.
Key Advantages of Data Mesh as Data Infrastructure
- Decentralized Data Ownership – Data Mesh promotes a sense of ownership and responsibility within individual domains, leading to better data quality and governance.
- Scalability and Agility – Autonomous data domains can scale independently, reducing bottlenecks and enabling faster innovation.
- Collaboration – Data Mesh encourages cross-functional collaboration, breaking down silos between domain experts and data practitioners.
- Domain-driven Approach – Data products are designed to meet specific business needs, resulting in more relevant and actionable insights.
Challenges Associated with Data Mesh
- Complexity – Managing multiple autonomous data domains can lead to increased complexity in data pipelines, integration, and governance.
- Cultural Shift – Adopting Data Mesh requires a cultural shift towards decentralized decision-making and collaboration.
- Data Consistency – Ensuring consistent and accurate data across different domains can be challenging.
- Initial Overhead – Setting up autonomous data domains and establishing standard interfaces can be resource-intensive.
Data Fabric: Unified & Integrated Data Management
As compared to Data Mesh, Data Fabric is a relatively new approach which has been in development for several years now. It focuses on providing organizations with a unified, integrated, and scalable data architecture. Data Fabric aims to create a cohesive data ecosystem by seamlessly connecting various data sources, applications, and analytics tools, thus enabling easier data access, discovery, and governance.
Data Fabric typically employs a centralized control layer that manages data orchestration and data quality across the entire organization. It abstracts the underlying data infrastructure and provides a consistent and unified view of the data, irrespective of its location or format.
Key Advantages of Data Fabric as Data Infrastructure
- Centralized Management – Data Fabric provides a unified control layer, simplifying data orchestration and governance.
- Data Accessibility – Seamless integration enables easy data discovery and access, enhancing analytics and decision-making.
- Consistency – Data Fabric ensures consistent data semantics and quality across the organization.
- Resource Optimization – Data Fabric optimizes resource utilization, thus reducing redundant data storage and processing tasks.
Challenges Associated with Data Fabric
- Lacks Agility – A centralized control layer in Data Fabric can hinder agility.
- Vendor Lock-in – Some Data Fabric solutions may lead to vendor lock-in due to proprietary technologies.
- Adaptation Complexity – Implementing Data Fabric may require organizations to make significant changes to existing data infrastructure and processes.
Choosing What’s Right for You – Data Mesh vs. Data Fabric
Deciding between Data Mesh and Data Fabric depends on your organization’s specific needs, existing infrastructure, and culture. Data Mesh is well-suited for organizations seeking to foster domain-oriented ownership, collaboration, and agility. On the other hand, Data Fabric could be a better fit for organizations aiming to simplify data access, governance, and integration through a centralized approach.
It’s worth noting that some organizations have even embraced a hybrid approach, combining aspects of both Data Mesh and Data Fabric to create a customized solution that best addresses their unique challenges. Ultimately, the choice boils down to the trade-offs your organization is willing to make between decentralization and centralization, and how well the chosen approach aligns with your strategic goals.
Data Mesh & Data Fabric: Industry Use Cases
- Retail & E-commerce – In the retail and e-commerce sector, Data Mesh facilitates personalized customer experiences by organizing data domains, such as purchase history, preferences, and inventory data. Simultaneously, Data Fabric integrates data from online stores, point-of-sale (PoS) systems, and inventory databases, providing real-time insights for optimized inventory management, demand forecasting, and pricing strategies. This synergy offers tailored shopping experiences while streamlining supply chains and operations.
- Healthcare – In healthcare, Data Mesh allows for efficient patient care with distinct data domains like electronic health records, medical images, and demographics — all of them managed by specialized teams. Data Fabric integrates data from various sources, such as electronic health records and billing systems, ensuring healthcare professionals can obtain critical insights for informed decision-making and improved patient care.
- Manufacturing – In the manufacturing industry, Data Mesh enhances production efficiency by organizing data domains, including machine performance, quality control, and supply chain data. At the same time, Data Fabric integrates data from production lines, sensor networks, and supplier databases, providing important and real-time insights into equipment health and supply chain disruptions.
- Banking & Finance – In the finance and banking industry, Data Mesh empowers risk management with distinct data domains like market trends, customer transactions, and regulatory compliance. Meanwhile, Data Fabric integrates data from various sources, such as trading platforms and customer databases, offering real-time insights for risk assessment and fraud detection.
- Transportation & Logistics – In transportation and logistics, Data Mesh improves dat-to-day operations by managing data domains related to supply chain, route optimization, and vehicle performance. Data Fabric integrates data from sensors, GPS devices, and shipping records, providing real-time tracking and insights to optimize logistics and delivery processes.
How Contata Helps Businesses to Modernize their Data Architecture
With over two decades of experience, Contata is a reputable data science and engineering company, providing cutting-edge data management solutions to businesses worldwide. Our data professionals leverage the latest tools and technologies to help organizations efficiently manage data to improve bottom line. Our Data Mesh and Data Fabric solutions focus on:
- Seamless Data Integration: We ensure effortless integration of data from various sources, be it databases, applications, or IoT devices. The goal is to provide you with a unified view of your data landscape, eliminating redundancy and ensuring consistency across the organization.
- Autonomous Data Domains: Our solutions empower decentralized data teams with autonomous ownership over specific data domains, fostering agility and quick decision-making. Your teams have direct control and accountability over the data while also adhering to government data standards.
- Scalable Data Processing: At Contata, we ensure that data processing is scalable and efficient. We follow a microservices-based architecture, allowing businesses to process data at the source, eliminating the need for extensive data movement. This approach results in faster insights and reduced strain on your data infrastructure.
- Real-time Insights: Contata helps businesses to manage data in real-time. Real-time data integration, transformation, and analytics provide a competitive edge by enabling quicker responses to market changes.
- Data Security & Compliance: Contata prioritizes data security and compliance. By centralizing data governance and access controls, we ensure that your sensitive information is always protected, while still enabling authorized users to access and analyze the data they need.
- Data Lineage & Traceability: Our data solutions come with robust data lineage and traceability capabilities. You can easily track the origin, transformations, and usage of your data, improving transparency, accountability, and compliance.
- Adaptability: Seamlessly adapt to changing data needs. As your organization grows, the data architecture can also be expanded to accommodate new data sources, types, and formats, ensuring you’re always ready for the next data challenge.
Conclusion
As data continues to be a driving force in modern enterprises, the debate between Data Mesh and Data Fabric remains vibrant. Each approach offers distinct advantages and challenges, and the decision should be based on a thorough understanding of your organization’s culture, goals, and technical landscape. By carefully evaluating these factors and considering the potential benefits of both paradigms, you can pave the way for a robust and future-proof data architecture that empowers your organization to extract meaningful insights and make informed decisions.